Overview
Given One Image — Generate Millions
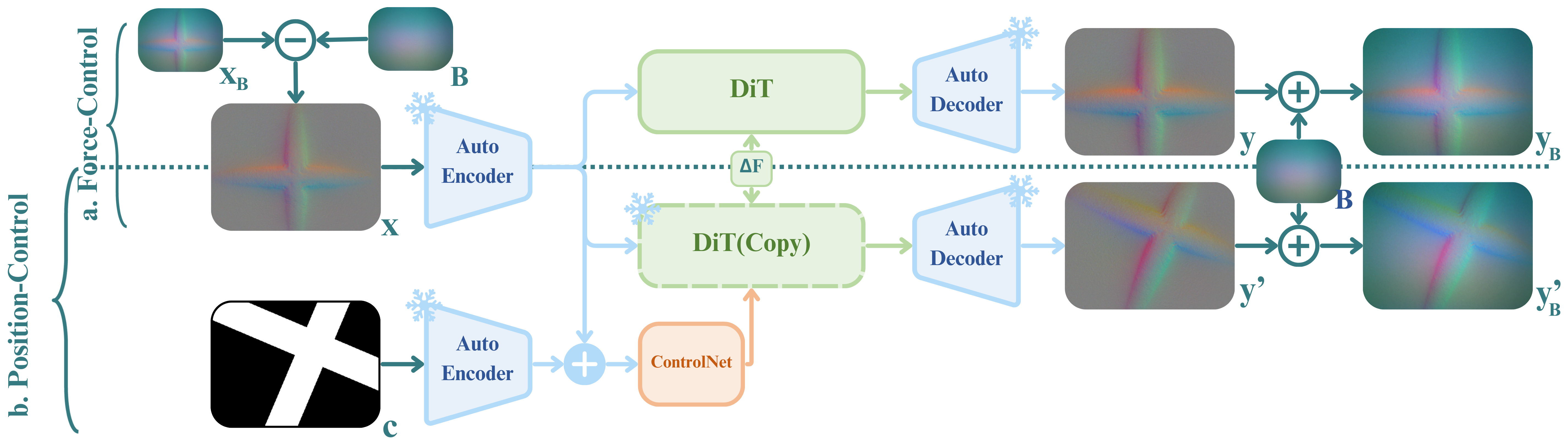
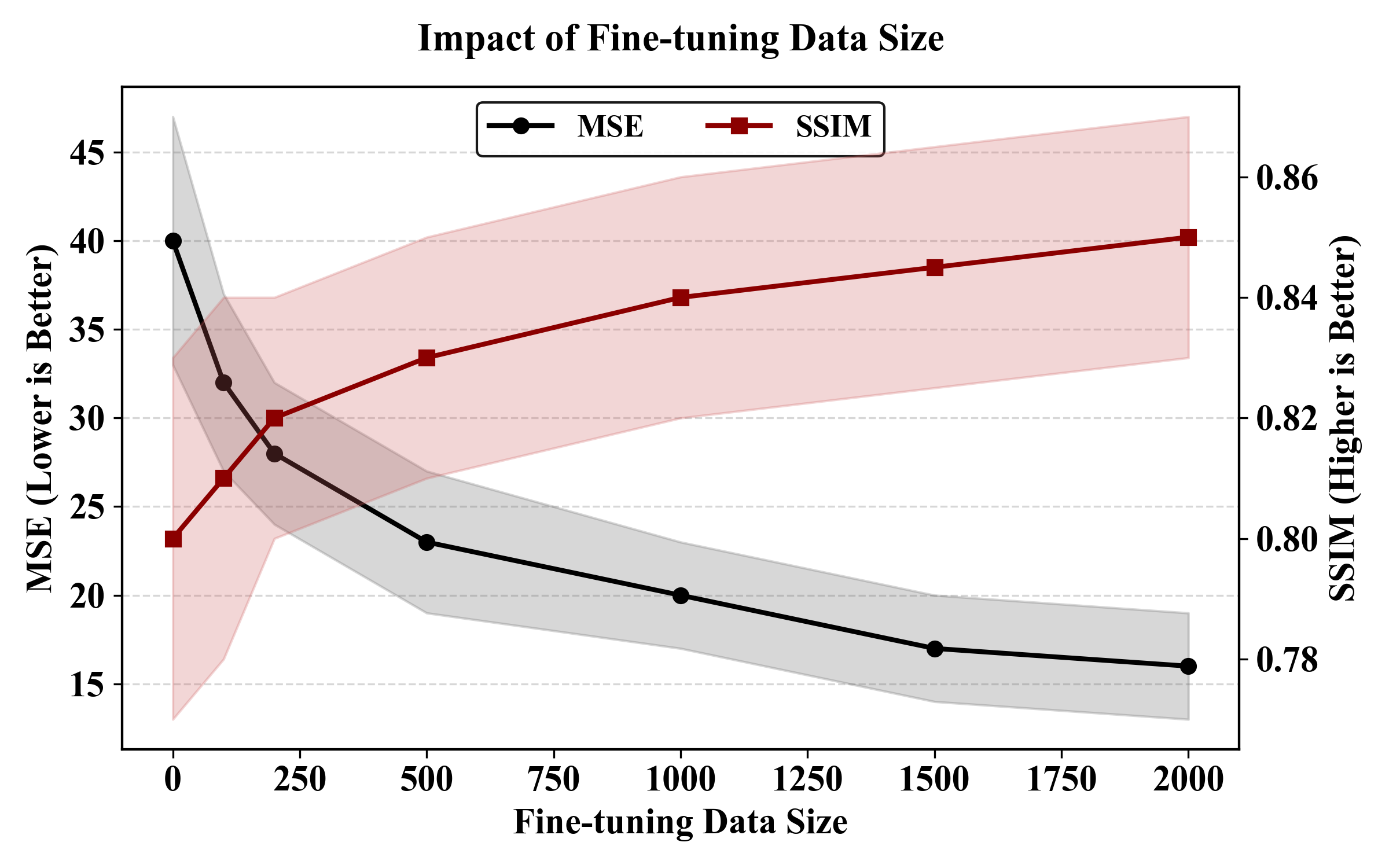
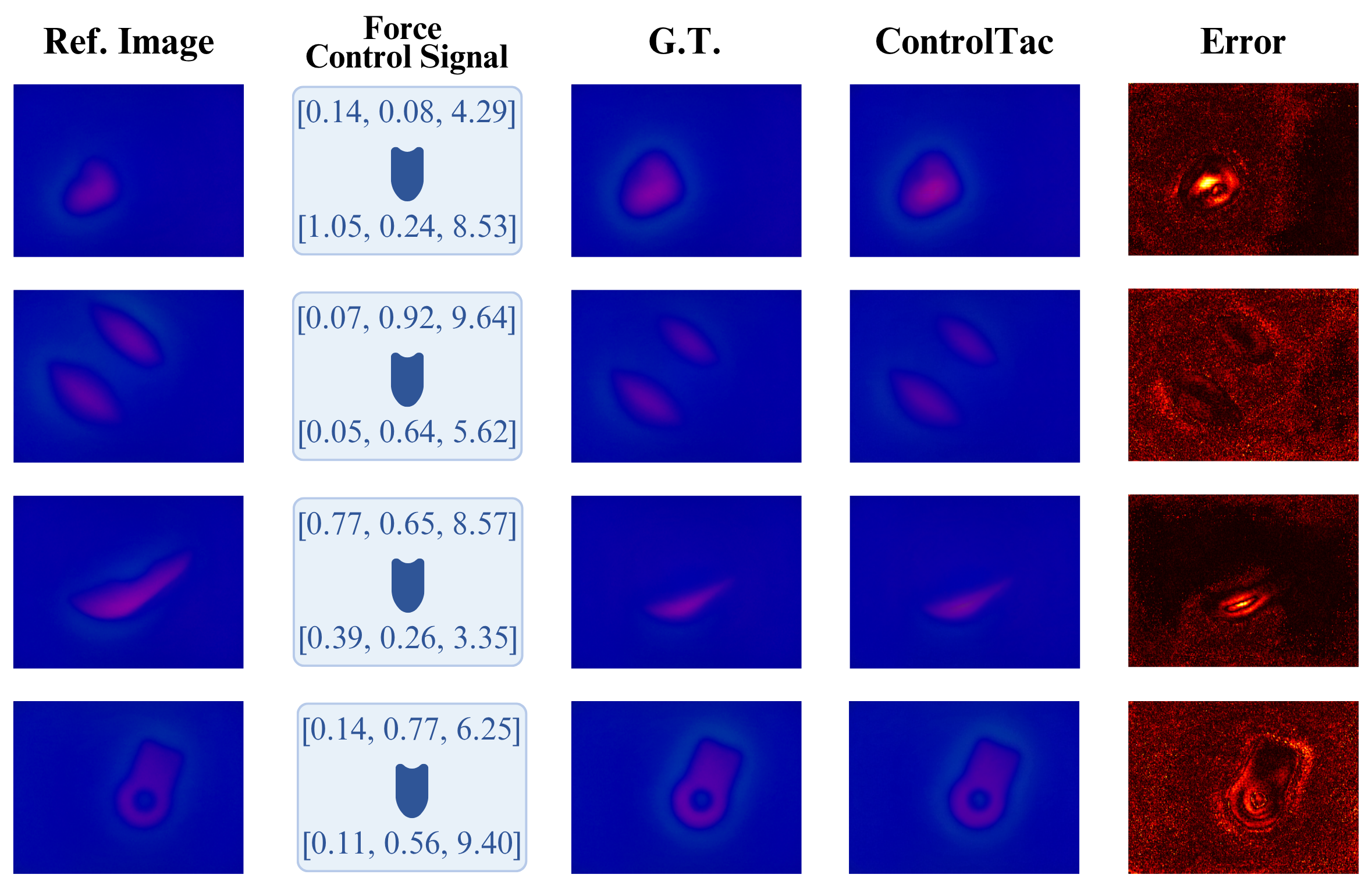
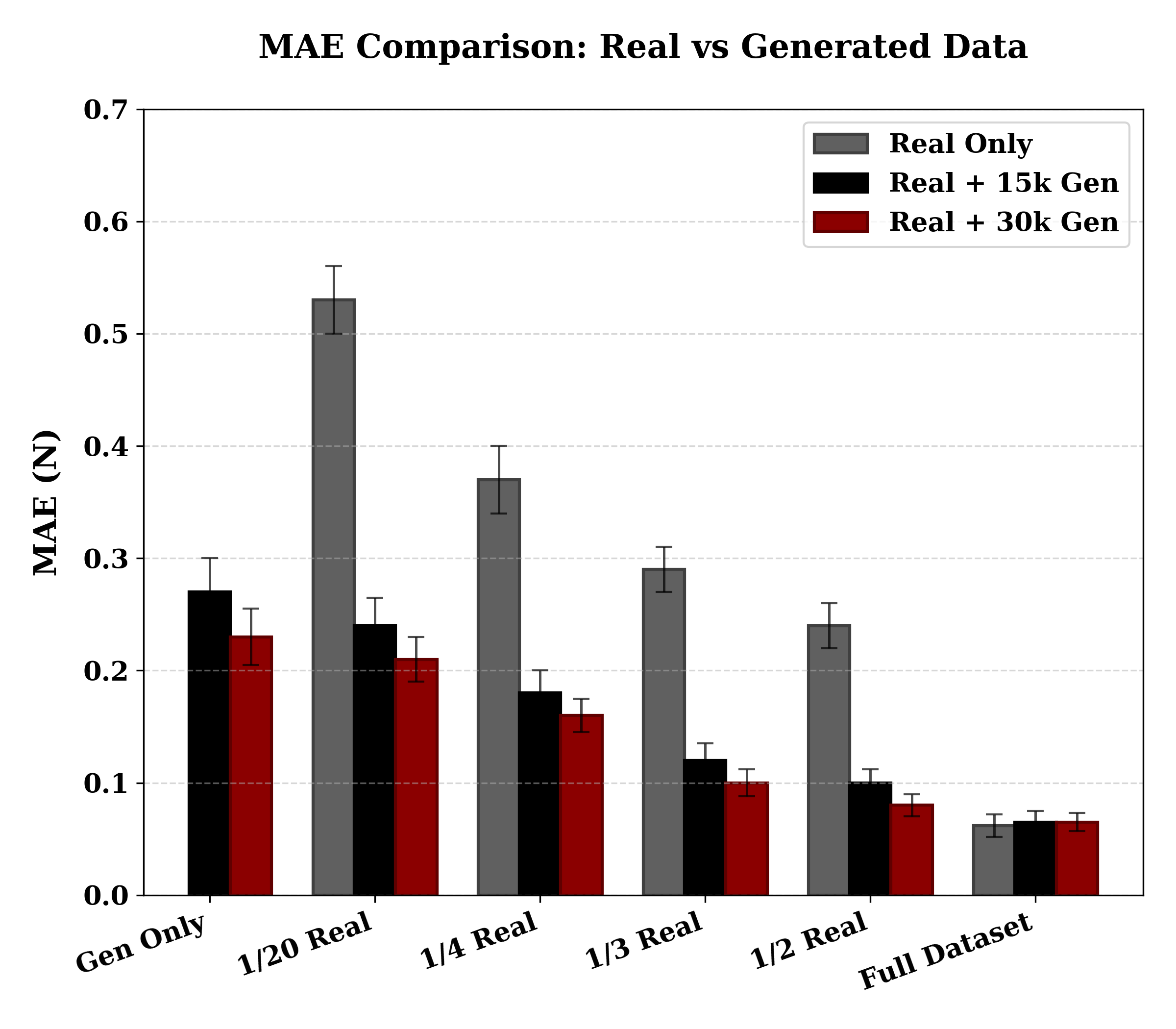
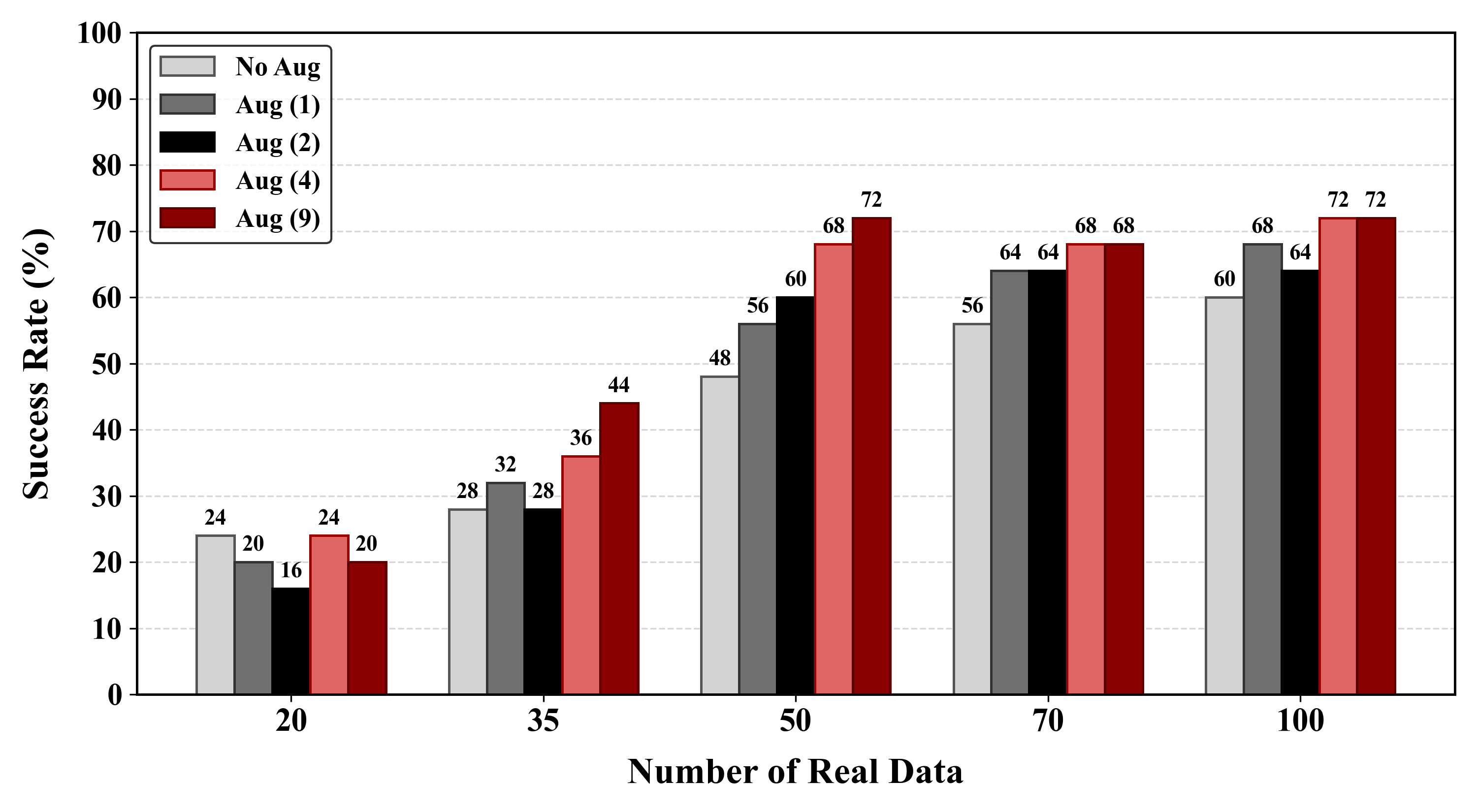
ControlTac performs force- and pose-conditioned generation to synthesize millions of realistic tactile images from a single reference, enhancing a wide range of downstream robotic applications.
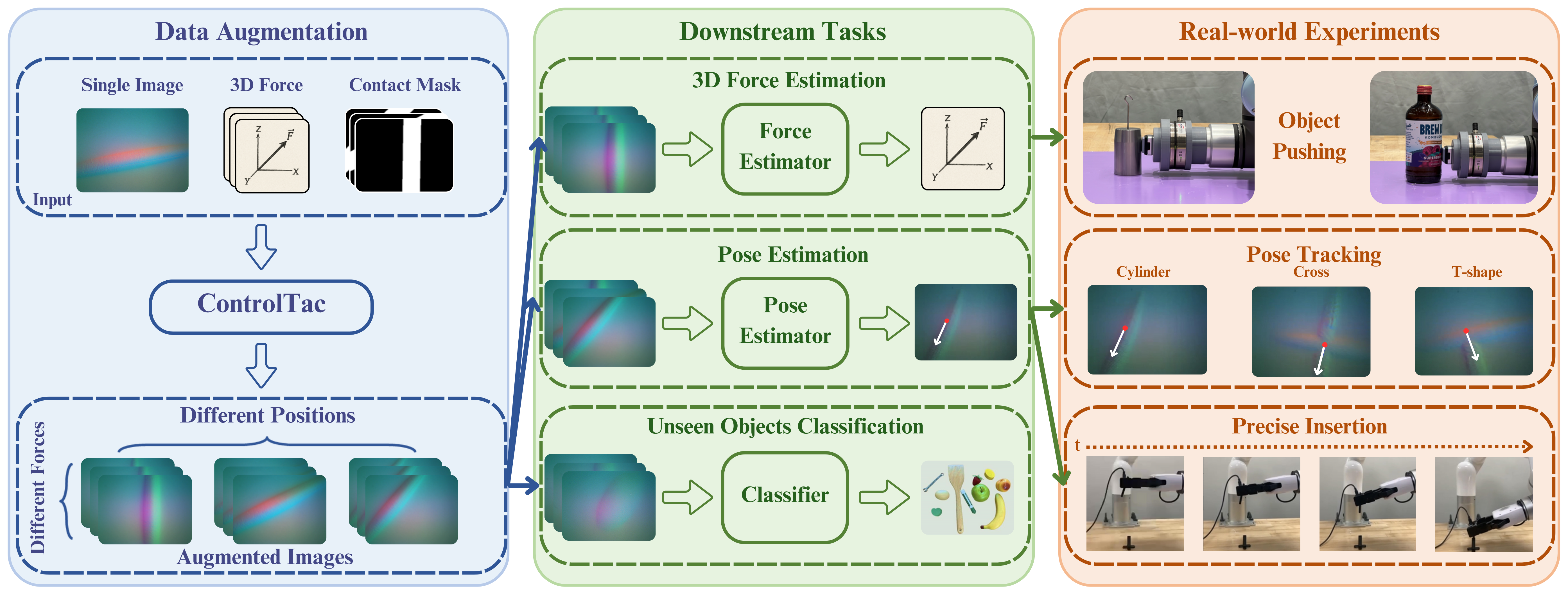
Figure 1. Overview of ControlTac. Given a single reference image, ControlTac performs force- and pose-conditioned generation to synthesize millions of realistic tactile images (center). This augmented dataset enhances various downstream applications, including object classification, weight estimation, real-time pose tracking, object insertion, and training imitation learning policies.